數(shù)據(jù)科學入門系列課程 數(shù)據(jù)存儲與計算、架構與選型全解析
整體流程與概念
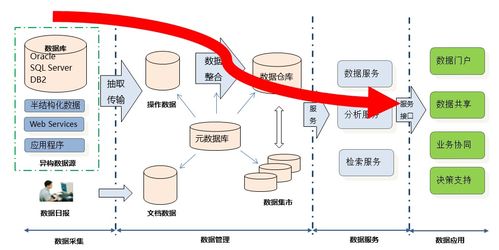
在數(shù)據(jù)科學中,數(shù)據(jù)存儲與計算是核心環(huán)節(jié)。整體流程包括數(shù)據(jù)采集、存儲、處理、分析和可視化。數(shù)據(jù)存儲負責持久化數(shù)據(jù),而計算則涉及數(shù)據(jù)處理、分析和模型訓練。高效的數(shù)據(jù)管理能夠提升數(shù)據(jù)科學項目的可擴展性和性能。
數(shù)據(jù)庫的選型
選擇合適的數(shù)據(jù)庫是數(shù)據(jù)存儲的關鍵。常見的數(shù)據(jù)庫類型包括關系型數(shù)據(jù)庫(如MySQL、PostgreSQL)、NoSQL數(shù)據(jù)庫(如MongoDB、Cassandra)和時序數(shù)據(jù)庫(如InfluxDB)。選型時需考慮以下因素:
- 數(shù)據(jù)結構:結構化數(shù)據(jù)適合關系型數(shù)據(jù)庫,非結構化或半結構化數(shù)據(jù)適合NoSQL。
- 讀寫性能:高并發(fā)寫入場景可選時序數(shù)據(jù)庫或分布式NoSQL。
- 擴展性:云原生數(shù)據(jù)庫(如AWS RDS、Google Bigtable)支持彈性擴展。
- 成本:開源方案(如PostgreSQL)可降低初期投入。
架構:Lambda vs Kappa
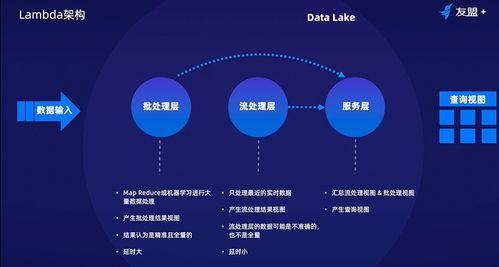
在數(shù)據(jù)處理架構中,Lambda和Kappa是兩種主流設計模式:
- Lambda架構:結合批處理和實時流處理。數(shù)據(jù)同時流入批處理層(如Hadoop)和速度層(如Apache Storm),最終由服務層合并結果。優(yōu)點是可處理歷史數(shù)據(jù)和實時數(shù)據(jù),但復雜度高。
- Kappa架構:簡化版,僅依賴流處理。所有數(shù)據(jù)通過流處理引擎(如Apache Kafka、Flink)處理,無需批處理層。優(yōu)點是架構簡單、維護成本低,適合實時性要求高的場景。
數(shù)據(jù)處理和存儲服務
現(xiàn)代數(shù)據(jù)處理和存儲服務提供高效工具:
- 數(shù)據(jù)處理服務:如Apache Spark用于大規(guī)模數(shù)據(jù)處理,AWS Glue用于ETL作業(yè)。
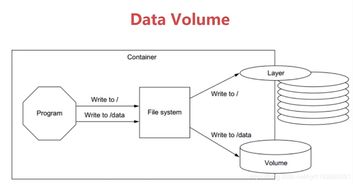
- 存儲服務:云服務如Amazon S3用于對象存儲,Google BigQuery用于分析型數(shù)據(jù)倉庫。
集成這些服務可構建端到端數(shù)據(jù)流水線,支持數(shù)據(jù)科學項目從原始數(shù)據(jù)到洞察的完整流程。
數(shù)據(jù)存儲與計算是數(shù)據(jù)科學的基礎,合理選型和架構設計能顯著提升項目效率。建議結合實際需求,選擇Lambda或Kappa架構,并利用云服務優(yōu)化數(shù)據(jù)處理流程。
如若轉載,請注明出處:http://m.ivanci.cn/product/6.html
更新時間:2026-06-12 07:34:08